Tagged: grammars
Language in Computer Science
The last post was about strings, so now something about languages. From the theoretical point of view a language is a set of words or more precisely sentences (strings). Possibly and usually an infinite set. Only sentences that are present in the set are part of the language, nothing else. Neat feature of languages is, that they interconnect two separate formal theories/models into one thing. Let me explain.
Language is a set. As in mathematical set. So anything that applies to sets applies to languages as well (like union, intersection, complement, Cartesian product). Members of any language are only strings. And there are some operations defined over strings (that is concatenation, reversal, sub-strings etc.). We can take advantage of this fact and abstract those, so they work with language as well. There is generally a lot you can do with a formal language either from the set or string point of view.
Definition 1. A formal language L over an alphabet Σ is a subset of Σ*. Formally, L ⊆ Σ*. The magical Σ* denotes a set of all existing words and sentences over Σ. Sometimes it’s called an alphabet iteration.
Like I said earlier, all operations defined for sets work with languages as well. For example language union L1 ∪ L2 = {s; s ∈ L1 ∨ s ∈ L2} etc. More interesting are the string operations that can be abstracted so they work on languages. There is language concatenation:
Definition 2. Let L1 be a language over Σ1 and L2 be a language over Σ2. Concatenation of these two L = L1⋅L2 = {xy; x ∈ L1, y ∈ L2} is a language over alphabet Σ = Σ1 ∪ Σ2.
Language concatenation as well as the string equivalent is not commutative operation. There is a couple of special cases:
- L ⋅ {ε} = L
- L ⋅ ∅ = ∅
The first, {ε} is a language with a single word — an empty string, in the second case we’re talking about an empty set. Concatenation can be looked at a sort of multiplication between the two languages (remember Cartesian product?). As a result of this thought, we define language power.
Definition 3. Let L be a language over Σ, then Ln denotes n-power of language and
- L0= {ε}
- Ln+1=Ln⋅L
With language power defined, we can advance to the last operation called language iteration. It’s basically an abstraction of language power.
Definition 4. L+ denotes positive iteration of language L defined accordingly
- L+ = L ∪ L2∪ … ∪ L∞
Definition 5. L* denotes iteration of language L defined accordingly
- L* = {ε} ∪ L ∪ L2∪ … ∪ L∞
Summary
In this post were introduced some of the most basic and most common operations that are defined on languages. The most important thing to remember is, that language is a set of sentences (or words) and the operations that we define originate from these two areas.
We have some set operations like union, intersection, complement as for generic sets. And we have abstractions for string operations like concatenation (notice, that it’s somewhat similar to cartesian product), language power and iteration.
Anyway, these couple of operations is nowhere near to the complete list of all existing functions for languages! After all, if you dive into some algebraic structures a little you can easily define your own :-).
Basic Computer Science
There is a couple of very basic definitions and axioms in computer science. I consider them to be very important, because everything that comes later is based on them. And if you don’t fully comprehend the basic stuff, it will be very hard to understand anything further. That’s why I decided to write a whole post on these trivial definitions.
Alphabet
Yeah, I’m not kidding. There’s a formal definition for alphabet. And what’s worse: it actually makes sense. I just wonder what would a kinder-gardener say on this :-D. Anyway, here it goes:
Definition 1.1. An alphabet is a finite non-empty set of symbols.
Alphabets are usually denoted by Greek big sigma Σ. A set Σ can be referred to as alphabet when it’s not empty, but also not infinitely big.
- Σ = {a, b, c} is an alphabet
- Σ = {0, 1} is an alphabet
- Σ = {} is NOT an alphabet
- Σ = all integers; is NOT an alphabet
Content of an alphabet are symbols. A symbol is some indivisible or atomic unit that can have some meaning (not necessarily). For example, if Σ = {righteous, dude} were alphabet, righteous and dude would be considered to be atomic indivisible elements (even though they contain multiple characters). Some folks also choose to omit the finite word from the definition. But that’s for some very advanced stuff and I’m guessing that finite alphabets will be more than sufficient for us.
String
Another fundamental thing is a string. String or a word is a sequence of some symbols (the order is important). Strings usually contain symbols from only one alphabet. In that case we say string 

Definition 1.2. Let
- empty string
is string over
- if
is a symbol from
is a string over
- y is string over
There are some more basic definitions like string length, concatenation, reversation that are useful and important, but they might be a little intimidating at first, so let’s skip ahead to languages.
Language
What is a formal language? We need to define 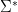
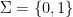
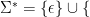
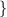
Then a formal language L over alphabet 
